





















Plant personnel often think of training on equipment as “hard” skills development, and the people side as “soft” skills, yet most everyone implicitly recognizes that the two are symbiotic. The 2016 Combined Cycle Users Group (CCUG) conference (San Antonio, August 22-25) focused on meeting the challenges of soft-skills development.
Many combined cycles today operate under what may be the most dynamic market conditions experienced in decades—ownership changing every few years; new rules, opportunities, and penalties taking hold in grid markets; growth in variable generation; an aging workforce; and ever-tighter environmental restrictions. Thus, it is even more critical that organizational development—often called people, policies, and procedures (3Ps)—reflect this dynamic environment.
Of course, it is also fair to say that the industry isn’t exactly in a period of prosperity. Electricity demand in most parts of the country is flat, low, or negative, consistent with anemic economic growth. Average wholesale power prices are at historic lows. Reducing overhead costs is a natural consequence and, a management priority. People cost money.
In short, not only do plants have to do more with fewer people, but those remaining must have a larger portfolio of skills to accommodate the greater uncertainties. If this isn’t enough, NERC’s reliability and physical and cybersecurity standards are moving many fossil plants towards 3Ps resembling nuclear plants. Thus, CCUG’s focus is timely and relevant.
Keep in mind that many of the programs you are exposed to may be largely fresh buzzwords attached to age-old processes and procedures. That doesn’t make them any less important, just that there are valid past experiences to draw from.
Copies of CCUG presentations supporting the highlights below can be accessed by registered users at www.powerusers.org.
Incident review
Mistakes and mishaps are inevitable. Learning from them as an organization is not. That begins with a formal post-incident review and remediation program. Having a framework or methodology to conduct one is essential. Three primary components are risk assessment, root cause analysis, and human performance review.
A representative from a small non-utility generator (NUG), in describing his company’s program, noted that characterizing the risk is what should drive the methodology. Incidents are partitioned into Levels 1-3 using Table 1, which shows the probability of occurrence versus consequences. Generally, Level 1 incidences are low-risk near misses, with discretionary remedial action. Level 2 incidents are characterized as OSHA recordable and/or less than $500K property damage, with remedial action taking place when appropriate or schedulable.
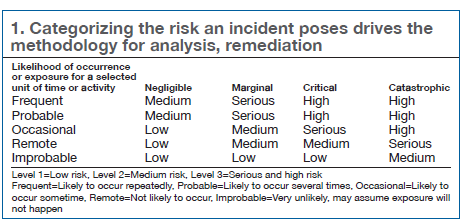
Level 3 incidents have greater than $500K property damage and represent serious risk to the business and personnel. These last incidents can be severe enough that the plant must be shut down until remedial action is taken.
Next step after characterizing the risk is analyzing the incident. The speaker advocated a simple root cause analysis (RCA). Low-risk events are usually analyzed and mitigated through a one-on-one discussion between the person or persons involved in the incident and the supervisor. Level 2 requires a formal RCA which is escalated in a Level 3 situation.
In the low-level incidents, the objective is to keep asking “why” something happened, with all answers grounded in facts and evidence, until the root cause is identified. For higher-level incidents, a formal cause and effect RCA is implemented, using wishbone diagrams (Fig 1).
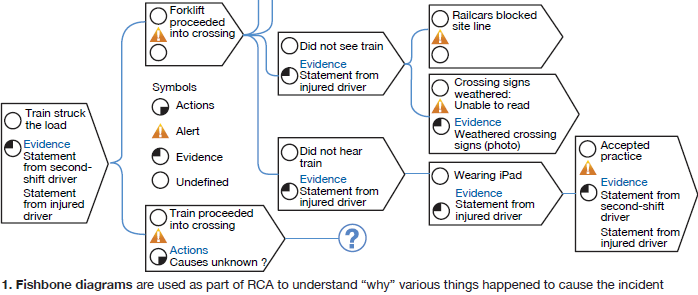
Once the root cause (or causes) is identified, a human performance review takes place to understand what led to the cause and how prevent the incident from recurring. Culpability may lie with the individual or with organizational weaknesses. Here, it is also important to look for generic implications across the fleet and make sure the conclusions and analyses are communicated.
Old-school techniques
An industry veteran from a California municipal utility stressed that old school techniques such as “walking down the plant” (Table 2) were still essential for identifying physical and cybersecurity gaps. Key is maintaining a healthy skepticism and questioning attitude.

His advice was also to deploy people who are not familiar with the systems; they will ask lots of new questions. Also, divide the plant into zones to make the job manageable and avoid “random” inspections. Anything that looks out of the ordinary or suspicious should be recorded—on cards, notebook, or audio or digital device.
Peer-to-peer audits with someone from a nearby industrial facility also were recommended. That is certainly a good way to have new questions posed about your facility, and discover gaps from your neighbor which might apply at home.
One security gap identified and mentioned in the presentation was tracking and discarding of uniforms and hardhats with the facility’s logo. These could be used by the wrong people to gain access, and obtained, for example, from a trash bin. In one case, an inspector at a peer facility was able to check out a company maintenance truck wearing a vest and hardhat. Guards decided it was okay to forego an ID check. The discovery led to a new policy at the powerplant to shred old vests and break old hard hats, rather than toss them into the garbage.
Another discovery was security camera sight lines partially blocked by vegetation.
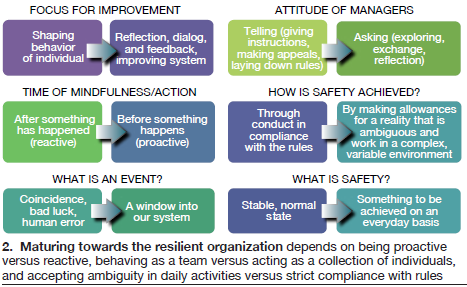
Old school reliability. Experience in applying techniques from the emerging field of “resilience engineering” was reviewed at length by representatives from one of the country’s largest combined-cycle owner/operators. From the material presented, it was clear that resilience engineering is simply an extension of reliability-centered practices to focus on anticipating changes and adapting to them.
Distinctions were drawn among reliable, resilient, and robust. Reliability is about an output, a result. Robust refers to something sturdy and solid, but “brittle,” whereas resilience is a system property of being able to self-heal. Resilient work teams (Fig 2), which learn to recognize early when something isn’t working right, rely on a diversity of knowledge and perspectives. Some of the thinking involved may be counter to traditional quality and safety methodologies, the presenters observed.
To push the resilience concepts out to the plants, this owner/operator relied on the center of excellence (CoE) approach. One plant was selected to be the CoE, adapt the practices of high-reliability organizations, and begin to think as a team, rather than a collection of individuals. Other facilities learn from the CoE plant.
One area identified for improvement—nothing new here, a source of performance errors for decades—is the shift turnover period. The “tool” employed as a lever of understanding and change is the after-action review, essentially a 360-review of the task following completion based on these questions:
- What was expected to happen?
- What actually happened?
- What surprised us?
- What went well and why (what should we do the same)?
- What can be improved and how (what should we do differently)?
- What did we learn that would help others?
The greatest “palpable” change for the plants, it was said, is the comradery felt by the site staff. A more concrete consequence, perhaps, is staff now practices O&M procedures before they are performed. These so-called human performance or human-factors-engineering techniques were instituted decades ago at nuclear plants.
In a sense, resilience engineering is what other manufacturing facilities went through in the 1980s when they had to face down the threat from overseas competitors. No longer could auto plants or steel mills operate “base load” and churn out the same product. They had to become more nimble, adaptable to customer needs. Thus, quality circles, total quality management (TQM), and continuous improvement techniques (quality oriented) took priority over the rote efficiency of production techniques (volume oriented) from earlier decades. Later these evolved into Six Sigma and other defects-management programs.
What powerplants have to do today is eliminate “defects” while responding to new requirements of their customers, usually the ISO or RTO or a utility managing greater ratios of variable generation in the daily mix.
STAR and STOP
Recognizing that 80% of all events are caused by human error (versus equipment failure) and that 70% of all human error is a result of organizational weaknesses, one western utility operating mostly in a regulated arena initiated a broad corporate human performance improvement (HPI) program. While it includes many of the concepts described above, three components important at the plant level are:
The self- or peer-check STAR technique—or stop, think, act, review.
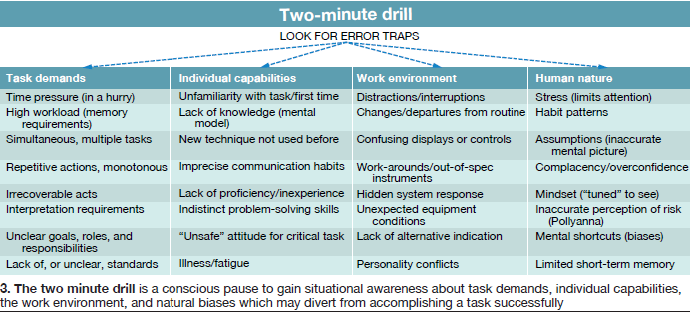
The two-minute drill—a conscious pause for situational awareness—Where am I? What am I going to do? What could go wrong? What hazards are lurking? How could another person get hurt? And so on (Fig 3).
STOP—a pause in task performance to ensure key details of the task have been addressed.
The goal of STOP is to “fail conservatively,” if for example, the task isn’t going as expected, anxiety is experienced, conditions have changed, assistance is required, and the task otherwise needs to be “stabilized.” Overall, the objective of the program is to provide very simple tools so that it is easy for plant staff to incorporate them into everyday culture.
What to expect with VPP
The OSHA Voluntary Protection Program (VPP) is a way to proactively manage safety while complying with OSHA regulations through partnering with the regulatory body. It is not for the faint-hearted, based on the nevertheless extremely positive experience of one plant in Virginia. Here are some of the characteristics and consequences of that experience:
- It took much longer than anticipated to set up the program and takes time beyond normal working hours.
- The plant submitted 85 pages of documentation to OSHA in support of the program.
- Recertification is required every three to five years.
- OSHA will show up unannounced to check up on plant staff behaviors related to safety and “they measure stuff,” for example the space between top ladder steps and platforms.
- If an inspector finds something during an inspection, you have until 4 p.m. that day to correct it; otherwise it goes into the official record.
- The plant added zone inspections to its monthly safety inspection activities and tailored corporate safety notebooks to be more site-specific.
- There’s “plenty of admin for VPP after the fact”—in other words, work doesn’t end when you get your VPP flag.
A hot topic arising from the experience was how many hours an employee can work. Apparently, there is no OSHA policy on the matter. It’s an important question—workers usually want as much overtime as they can get, but mental acumen deteriorates with lack of rest. This plant settled on 12 hours a day for seven days, arrived at by realizing that time for decompression, driving, eating, etc, has to be factored in. As a reference point, the plant’s major OEM contractor limits workers to 10.5 hours per shift.
A second positive consequence noted is that employees now hold contractors more accountable for their actions with respect to safety. This is also critical, as plants can have dozens or even hundreds of contractors onsite for outages, depending on what type of outage and how many units are affected. More attention is paid to escorts, sign-in procedures, and entrance security during outages. This facility went the “extra mile” and earned a VPP Star designation for its attention contractor safety.
Perhaps the greatest impact is that employees feel good about the program, they feel safe, according to the report at the meeting.
Knowledge management
The final soft-area presentations addressed plant knowledge management (KM) from two perspectives—transferring knowledge among members of the staff and the emerging digital asset intelligence platform. Over the next decade, 50% of workers in the electric power industry will be eligible to retire. KM includes concepts to ensure that mission critical knowledge doesn’t walk out the door.
The first presenter made a distinction between explicit knowledge which can be codified and articulated in language, and tacit knowledge residing in individual’s minds. Tacit knowledge is often not recognized as sharable, because it is so embedded as part of how that individual interacts with the equipment after so many years of experience. The important point is that deliberate, conscious methods must be cultivated, and time scheduled, to capture tacit knowledge for the benefit of the organization.
What is likely to replace much explicit and tacit knowledge in the plants, according to the second presenter, is the knowledge acquired and available for dissemination by the growing capabilities of the digital data and information systems—the hardware and software for control, automation, monitoring and diagnostics, archiving, and data analysis and trending. DAI is often represented by the buzz phrases big data, the industrial Internet, the Internet of things, and the digital or virtual plant.
According to this presenter, today’s dynamic operating environment is driving the integration of DCS/automation systems with once-disparate performance software capabilities towards a seamless platform (Fig 4). Many software and automation companies are vying to be the brand name on the outside; others will likely become “Intel Inside.”
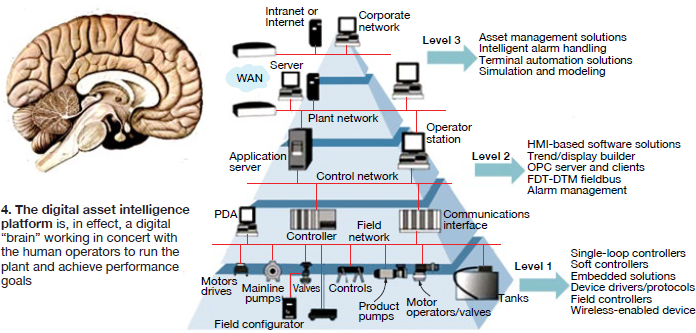
Advanced pattern recognition and data analysis lead to prognostic capability, an extension of M&D, or the ability to identify and mitigate anomalous equipment behavior well before it reaches an alert status in the alarm system. In other words, the system can detect potential issues before the typical control system alarms for the human operator.
Soon, according to automation platform suppliers, a digital version of the plant will be available to operate as a real-time simulator, allowing operators and engineers to “test” equipment modifications virtually and validate them before they are imposed on the actual equipment.
Automation systems can be designed to “close the loop” and make the decisions an operator otherwise would, although few seem willing to go that step today. In essence, a digital “brain” works alongside the human operators to achieve plant performance goals.
One analogy is the self-driving automobile, which is likely to become commonplace in five to 10 years, according to many reports. Most combined-cycle plants have so-called “one-button” automated start sequences (although operators are still required for some tasks). Today’s airplanes are largely run on auto-pilot; the human pilots are there, anecdotally, for passenger comfort, and of course to intervene under abnormal conditions.
The presenter suggested that the digital brain must be developed, designed, and nurtured over the lifecycle so that it reflects all of the relevant processes and procedures being applied (and described above) to achieve superior performance and avoid incidents, accidents, and catastrophic loss. Not only would such an exercise rationalize staffing with the digital capability, but ancillary benefits are probable in insurance costs, avoiding software duplication, re-considering sparing philosophy in light of advanced M&D and prognostics, better and more consistent performance, and others. CCJ